트리란
트리(Tree): 계층 구조(hierarchical)를 표현하는 비선형 자료구조. 노드(Node)들이 간선(Edge)으로 연결되어 있고, 사이클이 없다.
루트 노드(Root): 트리의 가장 위에 있는 노드. 부모가 없다.
부모/자식 관계: 어떤 노드 기준 한 단계 위를 부모, 한 단계 아래를 자식이라고 한다.
서브트리(Subtree): 어떤 노드를 루트로 하는 “작은 트리”. 트리 안에 포함된 부분 트리.
트리는 그래프의 특수한 형태: 사이클이 없고, 연결된 그래프의 한 종류로 볼 수 있다.
왜 트리임?
뒤집어 놓은 나무 모양: 위에 루트(뿌리), 아래로 잎(리프)이 퍼져 나가는 구조라서 트리라고 부른다.
계층 구조 표현에 적합: 조직도, 디렉터리 구조, 상속 관계처럼 “위–아래” 관계를 자연스럽게 표현할 수 있다.
부모–자식 용어 사용: 실제 나무나 가족 관계와 비슷한 메타포를 사용하기 쉬워서 이해가 직관적이다.

용어
노드(Node): 데이터와 다른 노드로 가는 링크(포인터)를 가진 기본 단위.
루트(Root): 트리의 최상위 노드.
부모(Parent): 어떤 노드의 한 단계 위에 있는 노드.
자식(Child): 어떤 노드의 한 단계 아래에 있는 노드.
형제(Sibling): 같은 부모를 공유하는 노드들.
리프/단말 노드(Leaf): 자식이 없는 노드. 가장 아래쪽 끝 노드.
내부 노드(Internal Node): 리프가 아닌 노드. 즉, 자식이 하나 이상 있는 노드.
레벨(Level): 보통 루트의 레벨을 0 또는 1로 두고, 아래로 한 단계 내려갈 때마다 1씩 증가한다.
깊이(Depth): 루트에서 해당 노드까지의 간선(엣지) 개수.
높이(Height): 루트에서 가장 깊은 노드까지의 깊이. 또는 “레벨 수 - 1” 로 정의하기도 한다.
노드의 차수(Degree of a node): 그 노드가 가진 자식의 수.
트리의 차수(Degree of a tree): 모든 노드의 차수 중 최댓값.
경로(Path): 한 노드에서 다른 노드로 이동할 때 거치는 노드들의 순서.
경로 길이(Path length): 경로 상의 간선 개수.
서브트리(Subtree): 어떤 노드를 루트로 하는 부분 트리. 원래 트리의 구조를 그대로 물려받는다.
트리 vs 그래프
공통점: 둘 다 노드와 간선으로 이루어진 자료구조이고, 인접 리스트, 인접 행렬 등으로 표현 가능하다.
트리의 특징 (그래프 중 특수 케이스)
- 사이클이 없다.
- 모든 노드가 서로 도달 가능한 연결 그래프이다.
- 간선 수 = 노드 수 - 1 이다.
그래프와 달리 트리가 갖는 추가 구조
- 하나의 루트가 존재한다.
- 루트에서 각 노드로 가는 경로가 정확히 하나만 존재한다.
- 부모–자식 관계를 명확하게 정의할 수 있다.
트리의 종류
일반 트리(General Tree): 각 노드가 자식을 몇 개든 가질 수 있는 트리.
이진 트리(Binary Tree): 각 노드의 자식이 최대 2개(left, right)인 트리.
포화 이진 트리(Perfect 또는 Full Binary Tree 의미로 쓰이기도 함): 모든 레벨이 꽉 차 있고, 모든 내부 노드가 자식 2개를 가진 이진 트리.
완전 이진 트리(Complete Binary Tree): 마지막 레벨을 제외하고는 모두 꽉 차 있고, 마지막 레벨의 노드들이 왼쪽부터 순서대로 채워져 있는 이진 트리.
이진 트리(Binary Tree)
정의: 각 노드가 최대 두 개의 자식 노드를 가지는 트리. 보통 왼쪽 자식(left child), 오른쪽 자식(right child)로 나눈다.
포화 이진 트리의 노드 수: 높이가 h일 때 노드 수는 2^(h + 1) - 1 이다.
이진 트리의 높이와 노드 수 개념:
- 높이가 h인 이진 트리의 최소 노드 수는 h + 1 (한쪽으로만 쭉 내려간 경우)
- 포화 이진 트리는 가장 빽빽한 경우
이진 트리 순회(Traversal)
전위 순회(Preorder): Root → Left → Right 순서로 방문.
중위 순회(Inorder): Left → Root → Right 순서로 방문.
후위 순회(Postorder): Left → Right → Root 순서로 방문.
레벨 순회(Level-order): 위 레벨부터 아래 레벨까지, 같은 레벨에서는 왼쪽에서 오른쪽 순으로 방문 (BFS처럼 큐 사용).
중요 포인트: 이진 탐색 트리(BST)에서 중위 순회를 하면 노드 값이 정렬된 순서로 나온다.
트리 탐색의 종류
DFS(Depth-First Search, 깊이 우선 탐색)
트리에서 한 방향으로 최대한 깊이 내려갔다가, 더 이상 내려갈 곳이 없으면 한 단계씩 되돌아오면서 다른 가지를 탐색하는 방식.
스택(Stack)이나 재귀 호출을 사용해 구현한다.
이진 트리에서 전위 순회, 중위 순회, 후위 순회는 모두 DFS 방식의 순회이다.
#include <stdio.h>
#include <stdlib.h>
typedef struct TreeNode {
int data;
struct TreeNode *left;
struct TreeNode *right;
} TreeNode;
TreeNode *createNode(int data) {
TreeNode *node = (TreeNode *)malloc(sizeof(TreeNode));
if (node == NULL) exit(1);
node->data = data;
node->left = NULL;
node->right = NULL;
return node;
}
TreeNode *insertLeft(TreeNode *parent, int data) {
if (parent == NULL) return NULL;
parent->left = createNode(data);
return parent->left;
}
TreeNode *insertRight(TreeNode *parent, int data) {
if (parent == NULL) return NULL;
parent->right = createNode(data);
return parent->right;
}
void dfs(TreeNode *root) {
if (root == NULL) return;
printf("%d ", root->data);
dfs(root->left);
dfs(root->right);
}
void freeTree(TreeNode *root) {
if (root == NULL) return;
freeTree(root->left);
freeTree(root->right);
free(root);
}
int main(void) {
TreeNode *root = createNode(1);
TreeNode *n2 = insertLeft(root, 2);
TreeNode *n3 = insertRight(root, 3);
insertLeft(n2, 4);
insertRight(n2, 5);
dfs(root);
printf("\n");
freeTree(root);
return 0;
}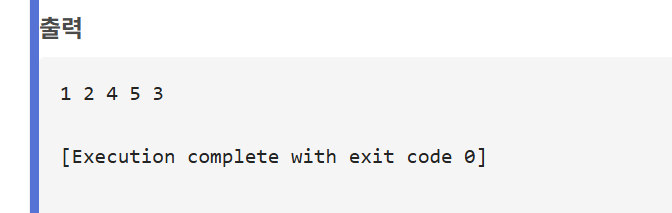
1
/ \
2 3
/ \
4 5
BFS(Breadth-First Search, 너비 우선 탐색)
루트에서 시작해서 같은 레벨(깊이)에 있는 노드들을 왼쪽에서 오른쪽 순서로 차례대로 방문하고, 그 다음 레벨로 내려가는 방식.
큐(Queue)를 사용해 구현한다.
이진 트리에서 레벨 순회(Level-order)가 바로 BFS 방식의 순회이다.
#include <stdio.h>
#include <stdlib.h>
#define MAX_QUEUE 100
typedef struct TreeNode {
int data;
struct TreeNode *left;
struct TreeNode *right;
} TreeNode;
typedef struct {
TreeNode *data[MAX_QUEUE];
int front;
int rear;
} Queue;
TreeNode *createNode(int data) {
TreeNode *node = (TreeNode *)malloc(sizeof(TreeNode));
if (node == NULL) exit(1);
node->data = data;
node->left = NULL;
node->right = NULL;
return node;
}
TreeNode *insertLeft(TreeNode *parent, int data) {
if (parent == NULL) return NULL;
parent->left = createNode(data);
return parent->left;
}
TreeNode *insertRight(TreeNode *parent, int data) {
if (parent == NULL) return NULL;
parent->right = createNode(data);
return parent->right;
}
void initQueue(Queue *q) {
q->front = 0;
q->rear = 0;
}
int isEmpty(Queue *q) {
return q->front == q->rear;
}
void enqueue(Queue *q, TreeNode *node) {
if (q->rear >= MAX_QUEUE) exit(1);
q->data[q->rear++] = node;
}
TreeNode *dequeue(Queue *q) {
if (isEmpty(q)) exit(1);
return q->data[q->front++];
}
void bfs(TreeNode *root) {
if (root == NULL) return;
Queue q;
initQueue(&q);
enqueue(&q, root);
while (!isEmpty(&q)) {
TreeNode *node = dequeue(&q);
printf("%d ", node->data);
if (node->left) enqueue(&q, node->left);
if (node->right) enqueue(&q, node->right);
}
}
void freeTree(TreeNode *root) {
if (root == NULL) return;
freeTree(root->left);
freeTree(root->right);
free(root);
}
int main(void) {
TreeNode *root = createNode(1);
TreeNode *n2 = insertLeft(root, 2);
TreeNode *n3 = insertRight(root, 3);
insertLeft(n2, 4);
insertRight(n2, 5);
bfs(root);
printf("\n");
freeTree(root);
return 0;
}
1
/ \
2 3
/ \
4 5이진 탐색 트리(Binary Search Tree, BST)
정의: 모든 노드에 key 값이 있고, 왼쪽 서브트리의 모든 key < 현재 노드의 key < 오른쪽 서브트리의 모든 key 조건을 만족하는 이진 트리
탐색(Search): 찾는 값과 현재 노드의 값을 비교해서, 작으면 왼쪽, 크면 오른쪽으로 내려가며 탐색한다.
삽입(Insert): 탐색 과정처럼 내려가다가 비어 있는 위치(NULL)를 만나면 그 자리에 새 노드를 삽입한다.
삭제(Delete) 기본 아이디어
- 자식 0개(리프 노드): 그냥 삭제한다.
- 자식 1개: 자식을 부모 쪽에 직접 연결해서 올린다.
- 자식 2개: 오른쪽 서브트리에서 가장 작은 값(중위 후속 노드) 또는 왼쪽 서브트리에서 가장 큰 값(중위 선행 노드)를 찾아 현재 노드를 그 값으로 대체한 뒤, 그 노드를 삭제한다.
시간 복잡도
- 평균: 탐색, 삽입, 삭제 모두 O(log N)
- 최악: 트리가 편향되면 O(N)
#include <stdio.h>
#include <stdlib.h>
typedef struct BSTNode {
int key;
struct BSTNode *left;
struct BSTNode *right;
} BSTNode;
BSTNode *createBSTNode(int key) {
BSTNode *node = (BSTNode *)malloc(sizeof(BSTNode));
if (node == NULL) {
exit(1);
}
node->key = key;
node->left = NULL;
node->right = NULL;
return node;
}
BSTNode *bstInsert(BSTNode *root, int key) {
if (root == NULL) {
return createBSTNode(key);
}
if (key < root->key) {
root->left = bstInsert(root->left, key);
} else if (key > root->key) {
root->right = bstInsert(root->right, key);
}
return root;
}
BSTNode *bstSearch(BSTNode *root, int key) {
if (root == NULL || root->key == key) {
return root;
}
if (key < root->key) {
return bstSearch(root->left, key);
} else {
return bstSearch(root->right, key);
}
}
BSTNode *minValueNode(BSTNode *node) {
BSTNode *current = node;
while (current && current->left != NULL) {
current = current->left;
}
return current;
}
BSTNode *bstDelete(BSTNode *root, int key) {
if (root == NULL) return NULL;
if (key < root->key) {
root->left = bstDelete(root->left, key);
} else if (key > root->key) {
root->right = bstDelete(root->right, key);
} else {
if (root->left == NULL) {
BSTNode *temp = root->right;
free(root);
return temp;
} else if (root->right == NULL) {
BSTNode *temp = root->left;
free(root);
return temp;
} else {
BSTNode *temp = minValueNode(root->right);
root->key = temp->key;
root->right = bstDelete(root->right, temp->key);
}
}
return root;
}
void freeBST(BSTNode *root) {
if (root == NULL) return;
freeBST(root->left);
freeBST(root->right);
free(root);
}
int main(void) {
BSTNode *root = NULL;
int keys[] = {50, 30, 70, 20, 40, 60, 80};
int n = sizeof(keys) / sizeof(keys[0]);
for (int i = 0; i < n; i++) {
root = bstInsert(root, keys[i]);
}
BSTNode *found = bstSearch(root, 40);
if (found) {
printf("찾은 키: %d\n", found->key);
} else {
printf("키 40을 찾지 못함\n");
}
root = bstDelete(root, 70);
found = bstSearch(root, 70);
if (found) {
printf("70 아직 있음\n");
} else {
printf("70 삭제됨\n");
}
freeBST(root);
return 0;
}
50
/ \
30 70
/ \ / \
20 40 60 80
50
/ \
30 80
/ \ /
20 40 60BST의 순회
#include <stdio.h>
#include <stdlib.h>
typedef struct BSTNode {
int key;
struct BSTNode *left;
struct BSTNode *right;
} BSTNode;
#define MAX_BST_QUEUE 100
typedef struct {
BSTNode *data[MAX_BST_QUEUE];
int front;
int rear;
} BSTQueue;
void initBSTQueue(BSTQueue *q) {
q->front = 0;
q->rear = 0;
}
int isEmptyBSTQueue(BSTQueue *q) {
return q->front == q->rear;
}
void enqueueBST(BSTQueue *q, BSTNode *node) {
if (q->rear >= MAX_BST_QUEUE) {
exit(1);
}
q->data[q->rear++] = node;
}
BSTNode *dequeueBST(BSTQueue *q) {
if (isEmptyBSTQueue(q)) {
exit(1);
}
return q->data[q->front++];
}
void bstPreorder(BSTNode *root) {
if (root == NULL) return;
printf("%d ", root->key);
bstPreorder(root->left);
bstPreorder(root->right);
}
void bstInorder(BSTNode *root) {
if (root == NULL) return;
bstInorder(root->left);
printf("%d ", root->key);
bstInorder(root->right);
}
void bstPostorder(BSTNode *root) {
if (root == NULL) return;
bstPostorder(root->left);
bstPostorder(root->right);
printf("%d ", root->key);
}
void bstLevelOrder(BSTNode *root) {
if (root == NULL) return;
BSTQueue q;
initBSTQueue(&q);
enqueueBST(&q, root);
while (!isEmptyBSTQueue(&q)) {
BSTNode *node = dequeueBST(&q);
printf("%d ", node->key);
if (node->left) enqueueBST(&q, node->left);
if (node->right) enqueueBST(&q, node->right);
}
}
int main(void) {
BSTNode n1 = {50, NULL, NULL};
BSTNode n2 = {30, NULL, NULL};
BSTNode n3 = {70, NULL, NULL};
n1.left = &n2;
n1.right = &n3;
bstPreorder(&n1);
printf("\n");
bstInorder(&n1);
printf("\n");
bstPostorder(&n1);
printf("\n");
bstLevelOrder(&n1);
printf("\n");
return 0;
}
50
/ \
30 70트리의 표현
포인터(링크) 기반 표현
- 각 노드가 자신의 자식 노드에 대한 포인터를 저장한다.
- 이진 트리의 경우 left, right 포인터 두 개를 둔다.
배열 기반 표현 (힙, 완전 이진 트리에서 자주 사용):
- 노드들을 배열 인덱스로 관리한다.
- 부모 인덱스가 i일 때,
왼쪽 자식 인덱스는 보통 2 * i 또는 2 * i + 1,
오른쪽 자식 인덱스는 2 * i + 1 또는 2 * i + 2 등 구현 방식에 따라 정한다.
부모 배열(Parent Array)
- parent[i] = i번 노드의 부모 인덱스.
- 트리 구조만 간단히 저장할 때 사용.
인접 리스트(Adjacency List)
- 그래프 표현과 동일하게, 각 노드가 연결된 노드들의 리스트를 가진다.
- 루트가 명확하지 않은 트리, 스패닝 트리, 일반 트리 등을 표현할 때도 사용된다.
트리의 장점
계층 구조 표현에 적합
- 디렉터리 구조, 조직도, 클래스 상속 관계 등 계층 구조를 자연스럽게 표현한다.
탐색 효율
- 균형 이진 탐색 트리 등의 구조를 사용하면 탐색, 삽입, 삭제를 O(log N)에 처리할 수 있다.
구간 연산에 유리
- 세그먼트 트리, 펜윅 트리를 사용하면 구간 합, 최소/최대값 등을 빠르게 처리할 수 있다.
재귀적인 구조
- 트리는 자체가 재귀적인 구조이기 때문에, 분할 정복 알고리즘을 적용하기 좋다.
출처: 교과서, C로 배우는 쉬운 자료구조, ChatGPT
'Data Structure' 카테고리의 다른 글
| [Data Structure] 그래프 (0) | 2025.10.29 |
|---|